程序运行时,每个变量都会找系统“借”来一块内存空间来存各种数据,使用完毕后再“还”给系统。系统会把还回去的内存又重新分配给别的变量去使用,如此循环。
既然是借来的,那就要有借有还。如果内存管理不当,申请内存的时候嘎嘎借,用完又不还给系统,时间长了,系统手上的空闲内存也会被消耗完,然后程序就崩溃了。
上面这个问题就是大家常说的“内存泄露”,这是一个很严重的bug。为了解决这个问题,编程语言分成了两个流派:手动管理派和自动管理派。
手动管理派的宗旨是“内存管理很重要,必须要交给人来管理”。其代表就是C/C++,所有的内存(严格来说是动态分配的内存)都要开发者亲自去new,用完再手动delete掉。
但人嘛,总有犯错的时候,特别是代码规模大起来之后,new语句和delete语句经常不在一个同函数里,稍微疏忽一下就会出现new了但是忘记delete,然后就内存泄露了。此时程序不会像除以零那样有明显的报错崩溃,而是直接忽略这个错误,代码继续往往前跑,就像什么事都没发生一样,时间久了就会吃光系统所有的可用内存,然后程序申请不了到新的内存了,就崩溃掉了。
后来随着计算机性能的发展,出现一种了自动管理内存的流派,宗旨是“内存管理很重要,人是会犯错误的,所以必须要交给计算机来管理”。其代表是C#/Lua/Python/Golang/JavaScript/Java这些语言。
这些语言的特点就是不用再像C/C++那样需要自己去delete内存了,写代码时只管new就好了,怎么爽怎么来。变量不用了直接置空,会有垃圾回收器去帮你自动释放内存。开发者的心智负担也降低了不少,可以把更多的精力放在开发业务上面。但是代价嘛,就是会降低一丢丢运行时的性能。
后来还出现了第三个流派,它既不需要开发者自己去new和delete内存,也没有运行时垃圾回收器会占用性能。可谓是独树一帜,程序跑的又快,内存又安全。不过这个不是今天的重点。
是第二种流派:自动内存管理派。
自动内存管理派里面其实也分两种策略:引用计数和根搜索(也叫引用树查询),这两种策略都可以达到自动内存管理的目的,只是实现方式有所不同而已。
目前使用比较多的都是根搜索策略,C#/Lua/Js/Java这些都是基于根搜索的自动内存管理,而Python是基于引用计数+根搜索相结合的策略。
一般来说,只要提起“垃圾回收”,大家默认都是指“根搜索”策略。
1.引用计数(Reference Counting)
引用计数其实是自动内存管理中,一个很特殊的存在,它和其它基于根搜索的回收方式有很大的不同,所以单独把它拿出来。
它的原理和它的名字一样,就是给引用的数量做一下统计。举个栗子,老师告诉教室里的同学:最后一个走的人要关灯。那么每个人走的时候,只要教室里还有别人,就不能把灯关掉。如果没有别人了,只剩自己一个了,就要关灯。如果教室里来了新人,也要把这个规则告诉这个新人,这样大概就是引用计数的原理了。
在程序内部,也会有一个变量值来记录引用数量。也就是当前的内存对象,一共有多少其它变量仍在引用。每增加一个引用就+1,每减少一个引用就-1。减到0就释放掉这个内存。
- 优点:内存回收时机是确定的,且几乎没有暂停时间
- 缺点:循环引用问题和更新引用计数的开销
我个人认为引用计数并不算狭义上的的GC,因为它没有独立的垃圾回收线程(根搜索是有的),内存回收时间是可预期的,且不会有暂停时间。
引用计数看起来是一个很完美的垃圾回收方案,原理简单可靠,回收时机也是确定的。但实际上它有一些比较大缺点,导致它无法流行开来。
首先最明显的就是循环引用问题,如果A,B两个对象都用引用计数做自动回收。此时A引用B,B又引用A。它会导致本应该被回收的两个对象,互相卡着对方无法满足释放条件(即引用数量降到0),然后就成了内存泄露。
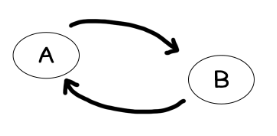
解决方法是将这两个强引用中的一个替换为弱引用,不过弱引用的引入又会增加使用上的复杂度,使用不当又会造成不该被释放的对被提前释放了,后续的访问又会出现悬垂引用的问题(Dangling Pointer)。而基于根搜索的回收方案,在进行垃圾回收是有状态的,会记录扫描过的所有对象,所以天然可以解决循环引用的问题。
这是一点,还有一方面是每次更新引用计数时,会有额外开销:(来源 Wikipedia)
- 更新引用的操作必须要是原子的,因为引用计数必须要保证线程安全,而原子操作比如原子加,原子减操作,比普通的非原子加减操作的开销都要大。特别是遇到修改引用计数特别频繁的地方,这个开销会进一步放大,开始变得不能忽视了。而对基于根搜索的策略来说,这个开销是零。
- 容易导致缓存失效(Cache Miss),因为每次更新引用计数,都要从内存中读取原始引用数量的值。这会导致CPU缓存失效,每次读值都要去访问主存。CPU一级缓存的访问大约1-2个时钟周期,而访问主内存则要上百个时钟周期,效率上差了一个数量级。
这两个缺点也导致了引用计数垃圾回收没法流行开来,尤其是循环引用的问题,相比后者的性能问题更加严重。
2.根搜索策略(Tracing Garbage Collection)
根搜索策略是从所有根对象(Root Objects)开始,搜索它们都直接引用了哪些对象。然后再搜索这些对象又引用了哪些对象,直到遍历到对象引用树的尽头为止,这个过程叫可达性分析(Wikipedia)。
接着所有被遍历到的对象,会被标记为存活对象,而哪些没有被遍历到的对象,则是要回收的对象。
这很好理解,首先根对象包括:函数栈帧(细分为局部变量和方法形参和寄存器),全局变量。
如果某个对象没有被局部变量、方法形参、寄存器、全局变量中任意一个引用的话。那我们在代码里是无法直接访问到这块内存的(直接按固定的内存地址访问的方法不在讨论范围内),既然我们无法访问这个对象,那它存在就没有意义了,就是一个要被回收的内存垃圾。
垃圾回收器在每分配一个内存对象时,都会把这个对象的信息加到一个列表里。这样垃圾回收器就可以统计出自己一共分配了多少个对象和查询到每个对象的地址和长度等信息了。
然后在进行对象的可达性分析时,又会把所有可达的对象放到另一个列表里。遍历完所有对象后,只要对比这两个列表,就能找出哪些对象不可达了,接着把它们回收就好。(当然在实际的实现中不会真的去分配一个新列表来存储可达对象,而是会用一些优化手段来做到相同的效果,文章这里只是举个栗子)
垃圾回收器在遍历对象的时候,会给每一个遍历过的对象打一个标记,代表已经遍历过了,无需再遍历。这个设计很好地避免了引用计数中循环引用的问题。但遍历的过程本身又多出了一些其他的问题,这个后面再讲。
接下来介绍几种常见的,基于根搜索的垃圾回收算法。
2.1.标记清除(Mark And Sweep)
标记清除的回收过程很简单,首先进行可达性分析,找到要回收的对象后,将其内存释放掉即可。(这里引用知乎大佬子非鱼制作的示意图)
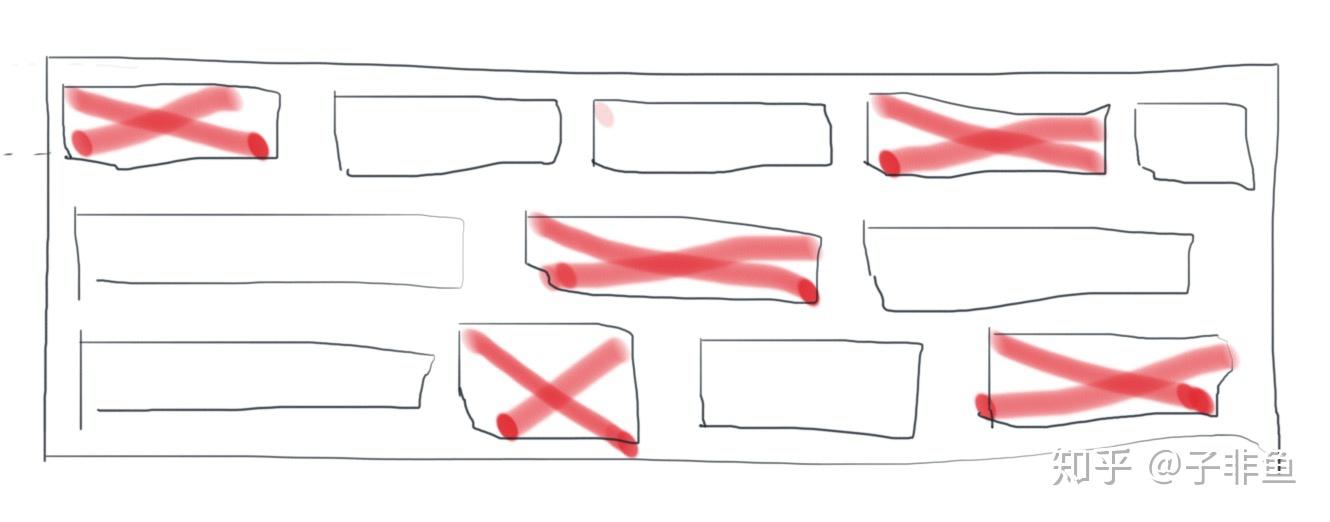
标记清除算法在每次回收完毕后,会记录下每个空档的位置和大小,并且全部放到一个链表里,叫“空闲链表”,等到下次要分配对象时,会优先从空闲链表里进行分配。
然后就会发现有个问题,存活的对象东一个,西一个,隔得很开。如果此时再要分配一个很大块的内存,可能没有任何一个空档能放得下了。

那么此时垃圾回收器就只能再去找操作系统再要一块新的内存区域来分配这个很大的内存了。这个内存块不连续的问题,就叫“内存碎片化”,会导致内存的利用率降低。
标记清除的缺点很明显:内存碎片化、分配速度慢(因为每次要遍历空闲链表)
同时它也有优点:没有内存移动和复制的开销(毕竟每次整理内存时的复制啊,移动啊,多少都是会有性能开销的)
2.2.标记压缩(Mark And Compacting)
标记压缩和标记清除类似,但是会在每次回收完对象之后,将存活对象进行整理,然后把他们挪到一起。
对象回收完成后出现大量的细小的空间,这些空间不连续。
接着把这些存活的对象全部移动到一起,这样后面的空间就连续了,可以放下更大的对象了,空间利用率就提高了。
优点是可以避免内存碎片化。缺点是每次移动对象都有开销。
2.2.复制算法(Copy Collection)
复制算法的回收过程和上面两种方法略有不同。首先将整个内存区域分成两半,左边一半和右边一半。
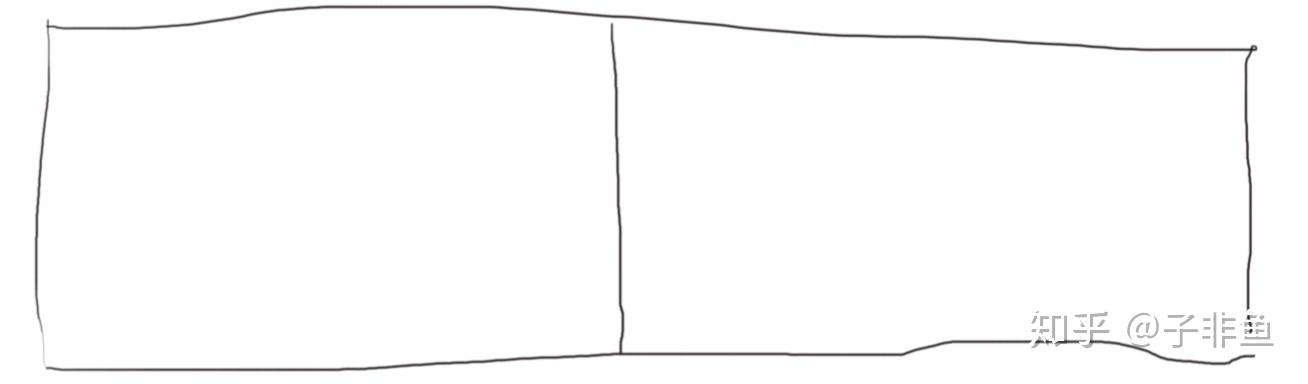
然后每次只使用其中一半,另一半先空在那里。每次回收时,会交换使用两个区域。也就是说这次使用左半边,执行垃圾回收后,就会改为使用右半边,再回收时又会用回左半边,如此循环。
假设现在正在使用左半边的内存。
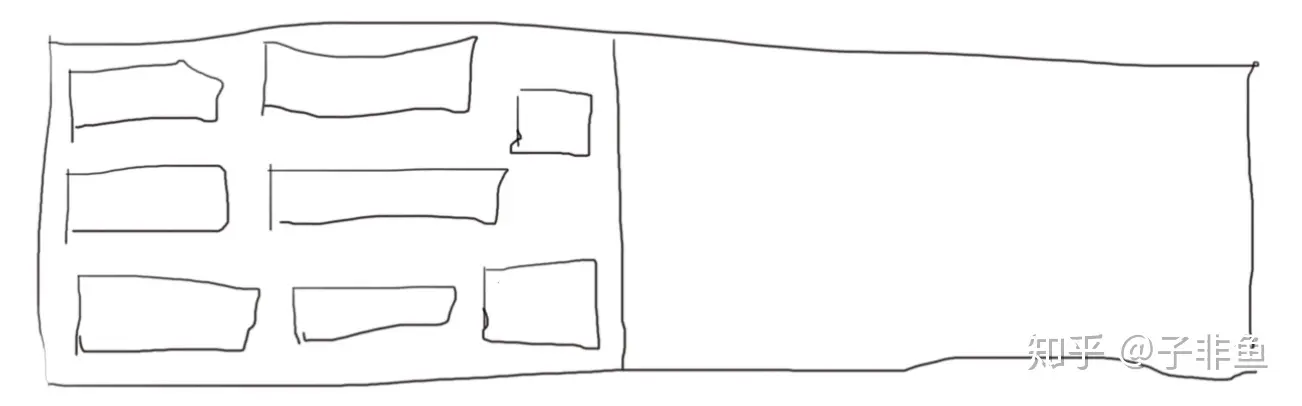
当触发回收时,会将所有存活的对象从左半边复制到右半边。
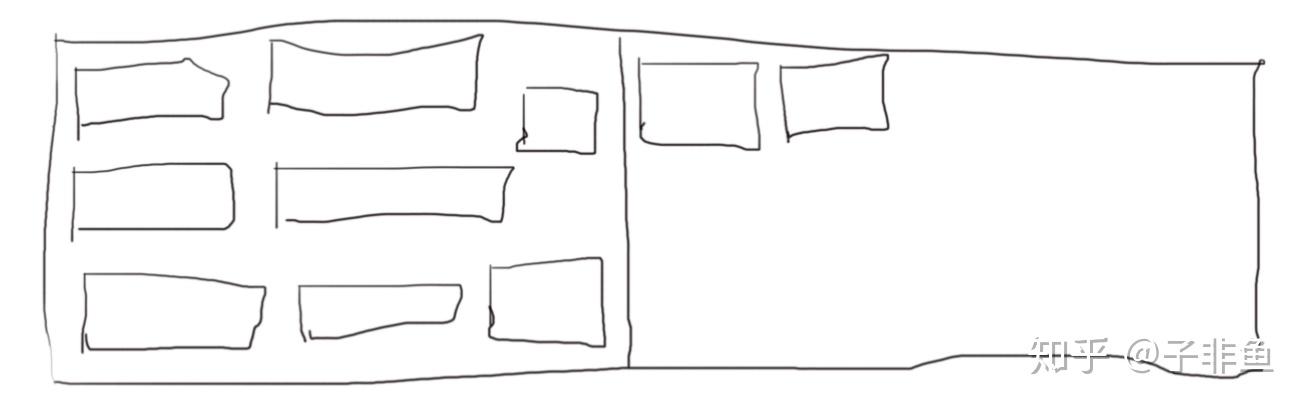
接着将左半边内存全部释放掉,新分配的内存就开始存到右半边,然后等右半边回收的时候,再把存活对象重新复制回左半边,就像这样左右两边循环使用。
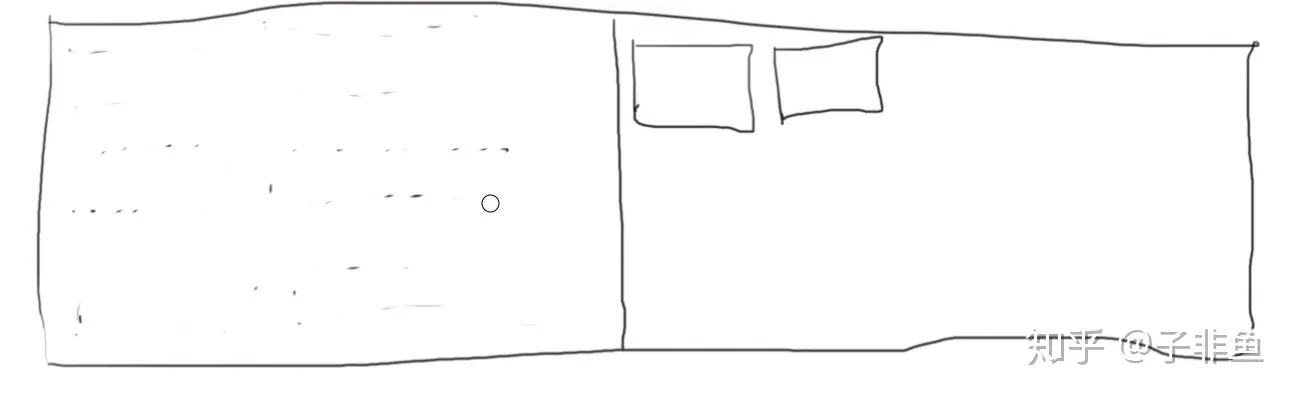
复制算法的优点是存活对象少的时候,回收效率高,因为要复制的对象就变少了。如果所有对象都存活了,那么就要把所有对象全部复制一遍,怎么看都很亏。
缺点除了上面提到的,存活率高的情况下回收效率不高以外。还有内存空间利用率低的问题,因为复制算法每次只能使用一半的内存,还有一半就只能预留在那里,没法使用。
分代垃圾回收策略(Generational GC or ephemeral GC)
准确来说,分代GC不是一个具体的回收算法,而是一个策略:针对不同特点的内存对象,分别应用不同的垃圾回收算法。
根据观察(出处:Wikipedia),刚创建的新的对象最容易被销毁,这些对象大多都是一些临时对象,用完就会丢弃的那种,这些对象叫“年轻代”的对象。
而经历过几次回收过后,仍然存活的对象,更加不容易销毁,这些对象往往是一些静态变量或者全局对象,生命周期特别长,这些对象叫“老年代”对象。
这些存活的年轻代的对象会进入下一代,也就是老年代中。
既然年轻代对象存活率低,那么就可以对这些对象使用复制算法来回收,复制算法的特点就是存活率的低的情况下,回收效率特别高。
而对于老年代对象,则比较适合使用标记清除或者标记压缩,这些算法的特点是对象存活率高的情况下回收效率高。
这样因地制宜的做法,相比只用单纯一种回收算法,其效率就提高了不少。
现代大部分编程语言的垃圾回收都会用到分代策略,这里为了举例只划分了2代,实际中可能会划分出3代,甚至4代,来进一步提升垃圾回收的效率。
移动内存对象
上面提到的几种自动内存管理方法中,有些算法会在回收垃圾时移动对象,有的则不会移动。比如引用计数和标记清除就不会移动,而复制算法和标记压缩则会移动对象。
如果不移动对象的话,程序运行时间长了可能会出现内存碎片化,当要分配一个大对象的时候,即使空闲空间的总量足够,但是却找不到一处连续的空间来,也会导致内存分配失败,降低内存的利用率。
看样子每次回收时移动内存对象才是更优解?其实并非如此,移动对象它也有自己的缺点,首先最明显的就是移动对象的过程是有开销的,会占用内存带宽,这个过程不是免费的。
其次就是内存的访问方式也会受限,当一个内存对象被移动之后,它的内存地址肯定会发生变化的,这时再按之前的内存地址去访问这个对象就会出问题,必须使用新的地址去访问。
拿C#来举例,内存分为两块,一块是垃圾回收器自动管理的内存,叫托管内存(Managed Memory),也就是平时在C#代码里面new出来的Class对象所占的内存。另一块内存则不是由垃圾回收器自动管理的内存,而是由C++层,开发者自己管理的内存,叫原生内存(Native Memory)。
如果从托管内存去访问这些移动的对象是没有问题的,垃圾回收器会确保你每次访问时都是正确的引用。而从原生内存直接访问就可能会出问题,因为垃圾回收器并不知道你从Native层引用了哪些托管对象,同时你也不知道托管对象什么时候会发生移动。有一种办法是将这些要与Native层交互的内存给固定在托管内存中,不让垃圾回收器去移动它们,就可以正常访问了。
而反观非移动式垃圾回收就不会有这个问题,因为每个对象都不会发生移动,所以和Native层交互就变得很容易了。
说完了移动式垃圾回收的两个缺点,现在来讲一下非移动式垃圾回收。首先它的优点是不移动内存,没有额外的带宽开销,同时在与Native层交互时也会更容易。
缺点是内存分配起来会比移动式垃圾回收要慢一些,这是因为移动式垃圾回收的内存是连续的,需要分配内存时,直接在最后一个对象的末尾进行分配就好了。
而非移动式垃圾回收会将每个空闲的小块内存,全部记录在一个空闲链表(Free List)里,分配的时候先从这个链表里找,看有没有足够大小的空闲块,如果有就直接分配,没有再分配到内存块的末尾。
可以看到相比移动式垃圾回收多了一个遍历链表的过程,特别是遇到大量的内存碎片化时,这个链表又会特别的长,遍历起来会更慢,直接雪上加霜。
这里有一个避免内存碎片化的小技巧,那就是在加载对象时,要先加载大的对象,再加载小的对象。因为计算机是有内存对齐这个说法的,所以几个大块内存加载后,中间大概率会有不少的小碎片空间,此时再加载小对象,就可以充分利用这些碎片空间了。如果加载顺序反过来,就吃不到这个优化的效果了。这个方法无论是移动式垃圾回收还是非移动式垃圾回收都可以使用。
保守式GC和精准式GC
GC其实还分两种:保守式GC(Conservative GC)和精准式GC(Precise GC),它俩最大的区别就是能不能精确识别垃圾。这个和前面提到的垃圾回收算法不同,这个更像是垃圾回收相关的一个特性,不会改变垃圾回收算法本身的逻辑。
比如一个对象A的地址是0x11223344,对象A此时已经要被销毁了,但同时又有个对象B,对象B有一个long类型的成员变量,值正好也是0x11223344。GC会不会把这个普通的数值给当做一个引用,然后阻止对象A正常销毁,这是个问题。
换做是保守式GC,它是无法判断一个long变量究竟是另一个对象的引用,还是一个普通的数值的,它只能靠猜。比如判断这个值是不是在托管堆的地址范围内,如果超出这个范围,那它肯定不是一个引用,而是一个普通的数值。
或者再去判断内存分配信息,查一下能不能找到和这个地址有关联的内存对象,如果找不到,那么它也不是有效引用。
毕竟是靠猜,总有猜错的时候。如果变量B里面恰好有个long值指向一个垃圾对象A,那么就会导致对象A也没法销毁。不过这种情况毕竟还是少数,总体来说对性能影响不大。
那保守式GC为什么要凭空多出这么个操作来呢,直接销毁不就好了吗,答案是不行,因为一个64位long变量和一个64位long类型的指针在运行时的数据是没有任何区别的,它们在计算机看来都是一串普通的二进制数。如果没有额外的类型信息,就算是人类,也是没法区分到底是个普通数值,还是一个对象引用的。
既然保守式GC没法区分到底是数值还是指针(引用),那么稳妥起见,把他们全部当做指针来看待好就了,所谓保守式GC,也就是保守在这里。毕竟如果把引用当做数值给忽略掉了的话,会导致指向的对象被意外销毁掉,从而出现悬垂引用,程序就执行出错了。再怎么说,内存占用稍微大一点,也比程序计算出错要可好的多。
此外,保守式GC也不支持移动内存对象(比如标记压缩算法),因为移动对象后,需要更新引用地址才能确保后续访问不会出现悬垂引用。而保守式GC它又没办法区别一个变量是引用还是普通的数值,如果把一个普通的数学运算的值当成引用给更新了,那么这个值后续所有的数学运算都会出现错误的结果,这相比性能下降一丢丢,显然又是不可接受的,毕竟性能差一点总比算出一个错误的结果要可接受一点。
再来说说精准式GC,这是目前的主流,它能依靠编译时生成的额外内存布局信息,来区分一个地址是普通的数值还是一个引用,从而可以更加精确的区别普通数值和垃圾对象,回收效率也比保守式GC更高。
但精准式GC需要编译器的支持,才能生成内存布局信息,如果编译器不支持,则只能使用保守式GC。
这里还有一个特例是C语言,可以把带有具体类型的指针比如int*在代码里手动转换成int类型存储,那么即使生成了内存布局信息也是无用的。虽然开发者心里清楚它不是一个数值而是个指针,但垃圾回收器它不知道,它觉得这就是普通的值,一旦垃圾回收器移动这个内存对象,又会出现悬垂引用的问题,所以也就只剩保守式GC这一个选择了。
双色标记和三色标记
大家肯定都或多或少听说过GC活动时用户线程会暂停。为什么会一定要暂停才能收回垃圾,这和垃圾回收时的遍历/扫描有关,垃圾回收器在遍历/扫描对象的时候,是不允许其它线程在运行的,因为只要有其它线程在运行,就有可能会修改某几个对象间的引用关系,这是不可接受的。没办法它只能选择把其它线程都停止,再开始扫描,运行结束再恢复其它线程的执行。
举个例子,老师在操场上清点学生人数时,会要求学生们站好不要乱动,老师才可以开始数人,如果老师从前往后数,数到一半,来了一个新学生站在队伍的开头,老师又不知道这个事情,最后就会漏数一个学生。
换到垃圾回收里也是同样的道理,垃圾回收器使用白名单机制做垃圾回收。也就是说有被“数”到“学生”,不会被销毁,没有被“数”到的“学生”,会被销毁。如果在回收期间不停止其它线程的运行,又恰好出现了这种喜欢“插队”的对象,那么这些“插队”的对象就会被误销毁。相比漏杀对象来说,误杀对象的后果更加严重,它会直接导致程序运行出错,而漏杀仅仅是增加一些内存占用。
1.双色标记收集方法
上面提到的需要一口气扫描完所有对象不能打断的方法,就是双色标记收集方法。在遍历开始之前,将所有对象标记成白色,然后开始根搜索扫描,所有走过的对象标记成黑色,然后再把所有没遍历到的对象全部回收即可。
双色标记它要求扫描时必须要暂停其它线程。暂停时间通常在几毫秒到几十毫秒之间,如果垃圾对象特别多,或者引用关系特别复杂,可能会高达几百毫秒甚至几秒。
有些游戏玩久了之后每隔一段时间就会小卡一下,正是GC在作怪,此时它正在回收内存。
GC带来的停顿大部分情况下是可以接受的,比如Web场景中,数据早到达几十毫秒和晚到达几十毫秒并没有太大的差别,甚至网络延迟都比这个时间要长。
同时GC的加入可以将更多的精力放到业务开发上,而不是操心怎么管理内存。这也是为什么大部分很火的编程语言都是带GC的,因为GC确实降低了开发的门槛。
2.三色标记收集方法
因为双色标记方法的缺陷,只能一口气把所有对象全部扫完,如果中间又让业务线程恢复运行了,那么之前扫过的结果就要作废,需要重头再扫。
为了解决这个问题,就出现了三色标记收集方法。使用黑白灰三色来标识每个对象:
- 白色:GC还未扫描过的对象,扫描开始时所有对象都是白色
- 灰色:GC仅扫过对象本身,还没有扫描完其所引用的其它对象,也就是扫到一半还没有完全扫好的对象
- 黑色:GC扫描过自己,也扫描过所有引用的对象
有了灰色的加入,现在垃圾回收过程就可以随时暂停了,如果一次要回收的内存压力太大,可以分多次回收,然后每次只扫描和回收一点,这样对用户线程的停顿就可以分摊到多帧里面了。
问题回到垃圾回收过程中,如果回收到一半,再将用户代码切出来执行后,此时引用关系肯定会被修改。随之而来的就是两个问:浮动垃圾和漏标。
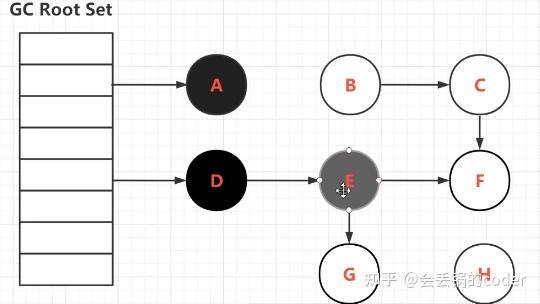
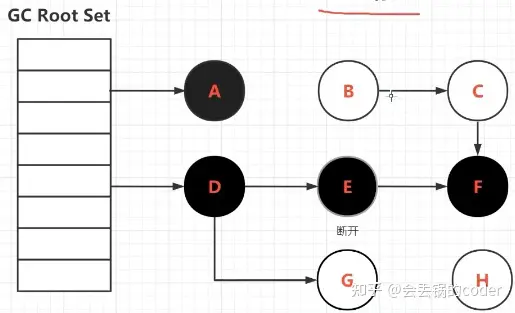
拿图举例(这里引用知乎大佬新生代农民工的插图)
当GC扫到一半时,会出现一部分是黑色对象,一部分是灰色,还有一部分则是白色。
此时GC暂停,让用户线程继续执行,然后再切回GC线程时,引用关系可能会被修改成这样。
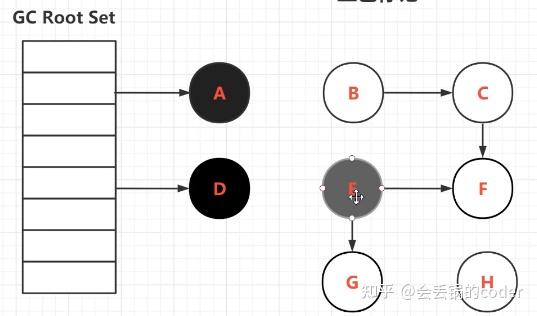
可以发现D到E之间的引用断开了,然后GC接着扫,扫完会是这样的情况。
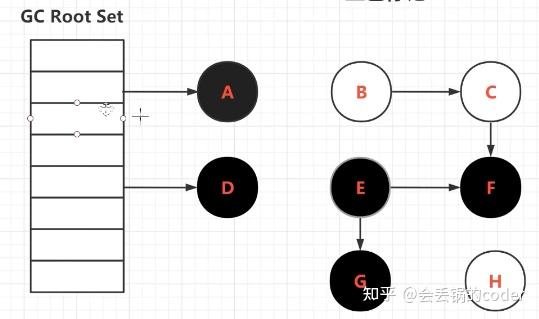
BCH木有扫到,是白色被正常回收没问题,但是EFG却变成了黑色,但他们本身有没有被A或者D对象所引用。那么EFG理应也是垃圾,但是EFG此时不是白色,也就无法被回收,这就是浮动垃圾,该被回收的对象没有被回收。
浮动垃圾本身影响并不是很大,因为下次进行垃圾回收时,它们又可以正常回收。
影响比较严重的是另一个问题:漏标。
我们从头开始开始,初始状态下引用关系是这样的。
扫描暂停时,用户断开了EG的引用,新增了DG的引用。此时GC扫描E时,发现E只引用了F。F没有引用任何对象,那么DEF这条引用分支线扫描完成,DEF也全部被标位黑色。
因为黑色代表一个对象本身和所有的子节点都被完整扫描过了,不用再重复扫描了,也就导致了垃圾回收器没能发现DG这条引用线,随后就把对象G当做了垃圾处理了。当再次从D访问G时,就会出现错误,这就是漏标问题,将不该被回收的对象给回收掉了。
浮动垃圾的问题并不需要专门去解决,因为下次垃圾回收的时候一样可以回收到这些垃圾对象。
但漏标的问题就比较严重了,会导致程序出现错误。不同语言的运行时针对这个问题都有不同的解决方法,拿Lua举例。
一种方法是前向写屏障,当黑色对象新增白色对象引用的时候,把这个白色对象置为灰色,这样下次GC时就可以从这个变为灰色的新对象开始继续扫描了。
另一种方法是后向写屏障,把这个黑色对象退回成灰色对象,这样也可以进行重扫。