经常会错过一些B站UP的直播,便想搭建一个录播机,把直播录制下来,等到自己有时间再观看。这样不仅不用担心赶不上直播,也能反复回看和快进,很方便。
经过一番摸索后,我找到一个还不错的搭建录播机的方案,分享给大家。
我的要求是这样,除了录下视频,还要能录下直播间的弹幕,另外观看也要方便一点。
最终我的方案是使用DDTV来录制,录制好后使用AList进行在线观看,这是最终效果,和看视频一样,也是有直播间弹幕的。(岷叔经常凌晨三四点直播,我都睡了完全看不到)
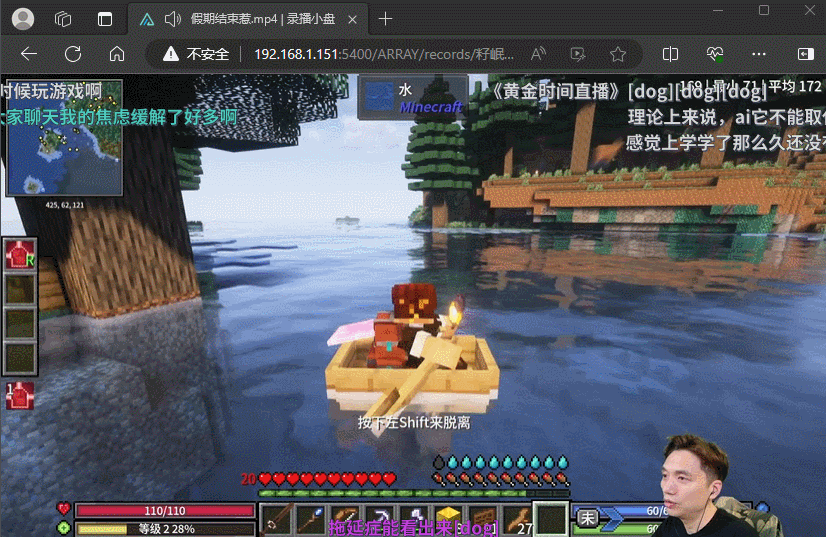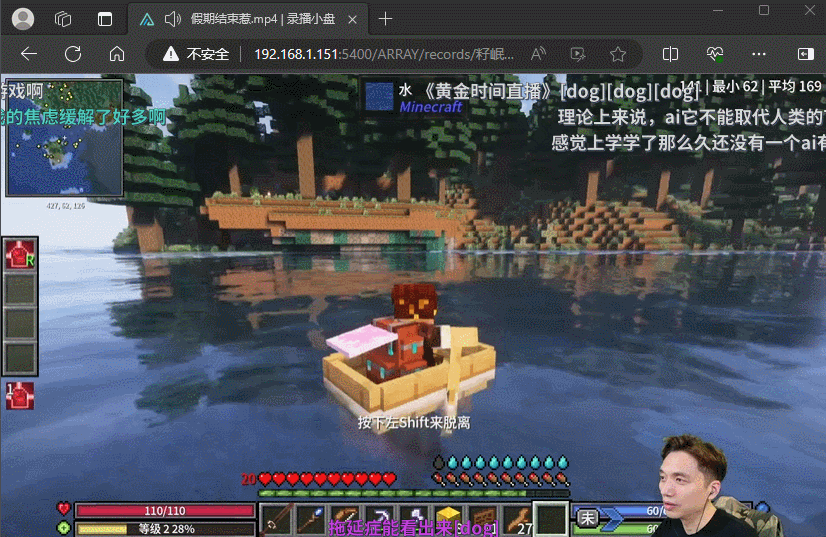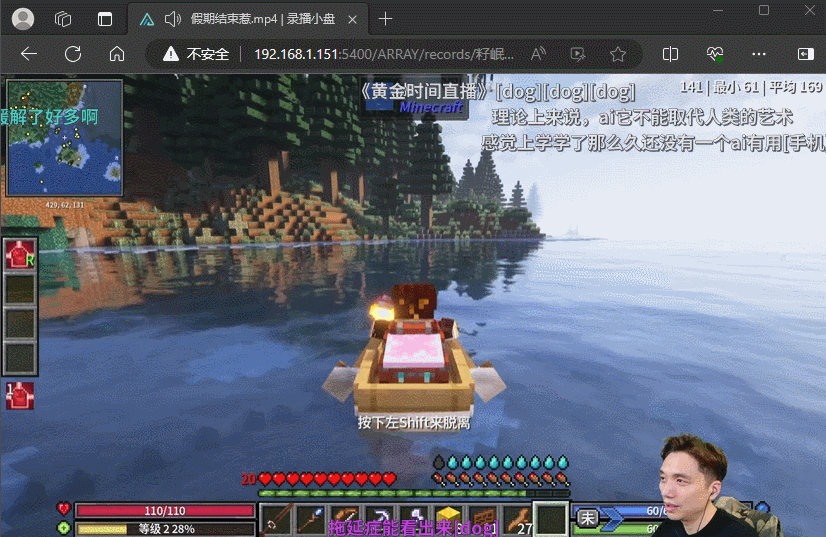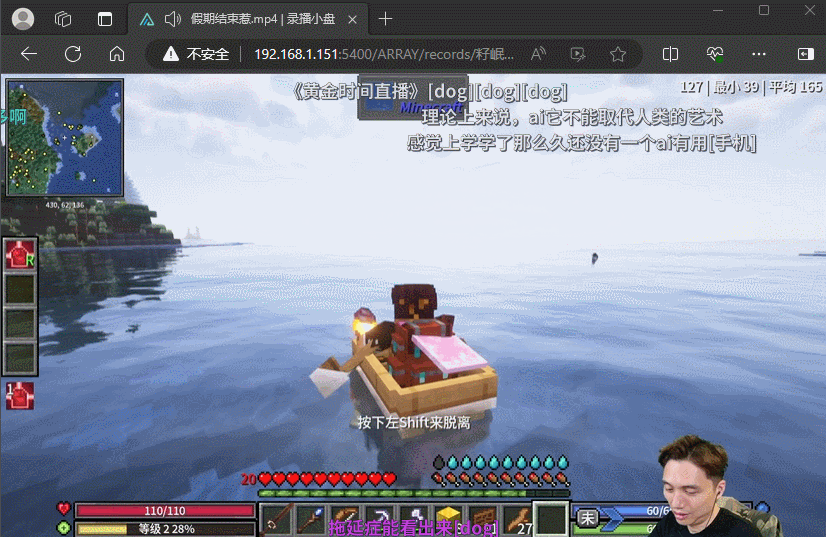
接下来就是教程了,使用Docker部署,这里使用docker compose来管理容器。
首先创建一个docker-compose.yml文件:
version: '3'
services:
ddtv:
# ddtv有三个版本,这里使用最小的cli版本
image: ghcr.io/chkzl/ddtv/cli:debian
container_name: ddtv
restart: unless-stopped
environment:
- "PUID=0"
- "PGID=0"
volumes:
# 这里我建议是把整个/DDTV目录挂载出来
# 这个目录包含配置文件,和ddtv的热更新数据
# 后续调试文件和修改配置会更方便
# (这里直接挂载到同目录的ddtv_data文件夹下了)
- ./ddtv_data:/DDTV
# 这个是录播的视频存放的目录,虽然它也在容器的/DDTV目录下
# 但还是建议单独挂载到别的地方,比如外接的硬盘里
# 因为录播视频的大小会非常的大
# 我这里是直接挂载到了一个raid0的阵列里面
# 所以需要把/mnt/array/records换成你自己的目录
- /mnt/array/records:/DDTV/Rec
alist:
# alist的话可以选择任意版本,这里就默认3.33了
image: xhofe/alist:v3.33.0
restart: unless-stopped
container_name: alist
environment:
- 'PUID=0'
- 'PGID=0'
- 'UMASK=022'
# 暴露端口不如外面没法访问alist
ports:
- '5400:5244'
volumes:
# 这一行是挂载alist自己的数据目录
- './alist_data:/opt/alist/data'
# 这里把录播文件夹也挂载到alist容器下,好从网页观看
- '/mnt/array:/array'
# 这里我还把ddtv的数据目录也挂载了
# 这样就可以很方便地在alist网页端修改ddtv配置文件了
- ./ddtv_data:/ddtv_datacompose文件写好后,需要在旁边创建两个目录alist_data和ddtv_data
接着启动docker。
启动成功后,注意观察alist的日志,alist首次启动时会创建一个admin用户,同时给admin生成一个随机的密码,输出到终端里。这里注意复制一下,因为它只显示一次,不保存就没了。
接着我们打开alist的页面,这里使用127.0.0.1:5244就可以打开,然后使用admin用户名和刚刚复制的密码进行登录。
登录之后直接进入AList的后台管理页面,点击“存储”页面,添加两个存储。
第一个存储的驱动选择“本机存储”,挂载路径填写/DDTV_DATA(当然这个名字可以随意取),根文件夹路径填写/ddtv_data。意思是把容器的/ddtv_data目录挂载到alist里的/DDTV_DATA这个路径下,后面就可以使用/DDTV_DATA文件夹来在线修改ddtv的配置文件了。
第二个存储的驱动也选择本机存储”,挂载路径填写/ARRAY(当然这个名字可以随意取),根文件夹路径填写/array。意思是把容器的录播文件夹/array挂载到alist的/array这个路径下,后面就可以使用/array文件夹来观看录播视频了。
这里说一下,挂载路径和根文件夹路径不一定要名字一样,不一样也是可以正常读取到的。
第一次启动时,除了alist会生成默认admin账号以外,ddtv也会下载和更新一些依赖文件。同时ddtv还会要求我们登录B站账号,这里建议创建一个小号来进行录播。
登录方式主要靠扫码,Docker环境下好像是没法直接扫码的,我们需要手动打开ddtv数据目录下的二维码图片进行扫码。
此时我们已经配置好了alist,就直接从alist这边进行操作了。
打开刚挂载好的/DDTV_DATA这个ddtv的数据目录。找到BiliQR.png文件并打开。就可以看到二维码了,掏出手机扫码就好。
扫码后ddtv会自动完成登录,没问题后我们就可以进行下一步,配置要录播的直播间了。
打开RoomListConfig.json文件,点击Markdown按钮,然后选择用Text Editor打开,这里面就记录了所有要录播的直播间数据。
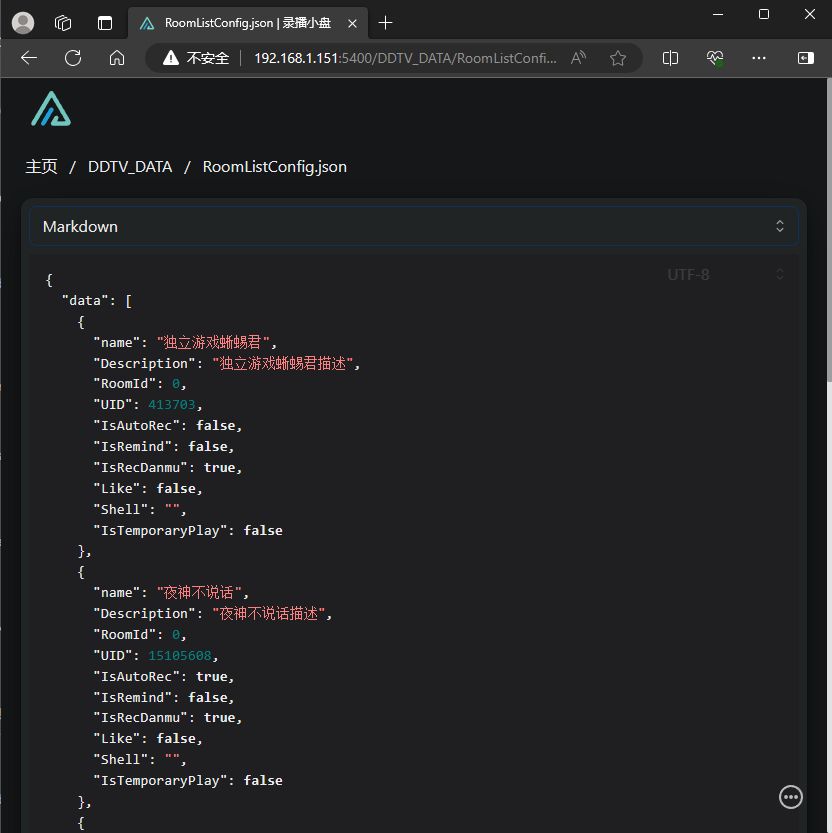
这个文件是json格式,每增加一个直播间都需要在data下新增一个json对象。这里简单说明一下每个参数的作用。完整的说明可以参考ddtv的文档
{
"name": "籽岷",
"Description": "籽岷",
"RoomId": 0,
"UID": 686127,
"IsAutoRec": true,
"IsRemind": false,
"IsRecDanmu": true,
"Like": false,
"Shell": "",
"IsTemporaryPlay": false
}- name:up主的名字,这个参数会被用来生成录播文件的文件夹的名字,可以写中文,一般与up名字相同即可
- description:描述,目前好像没有发现有什么作用,可以随便写
- roomId:直播间的房间号(房间号选项已经被废弃了,建议使用下面的uid进行替代)
- uid:主播的b站账号uid
- IsAutoRec:是否开启自动录制,肯定要开啊,不然怎么录制呢
- IsRemind:开播时是否发起通知,这个选项只有ddtv桌面版有作用,这里cli版本的ddtv没有效果
- IsRecDanmu:是否录制弹幕礼物信息,选择开启,没有弹幕乐趣少一半
- Like:特别标注。目前还没有实装这个功能,没有实际效果
- Shell:录制完成后会执行一个shell命令,好像可以实现一些高级效果,这里留空
这样就配置好了。我们重启docker即可生效,这样就会自动开始录制了。
录制完毕后大概会有这些文件:
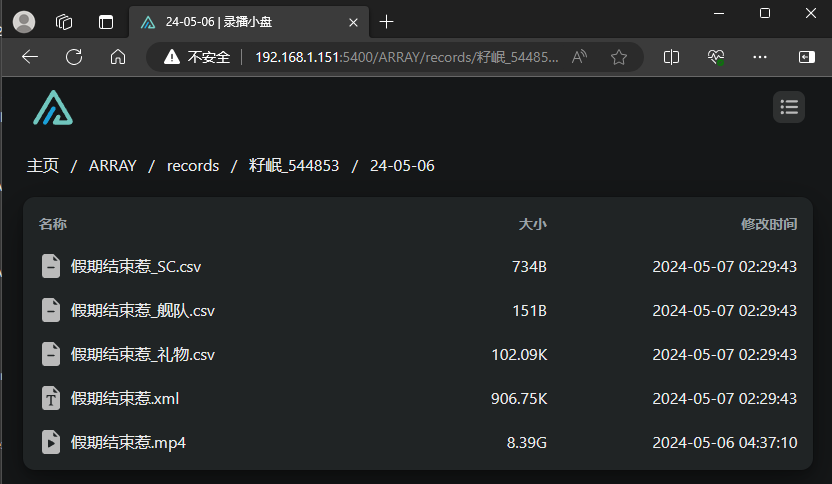
其中比较重要的是mp4文件和xml文件,mp4是视频文件很好理解。xml是弹幕文件,记录了直播间所有的弹幕信息。
之所以选择AList也是因为这一点,它可以直接读取xml弹幕文件并播放,不用再另外转码,很是方便!
我们点击mp4文件后,它就会自动加载弹幕了,不需要做任何额外工作。
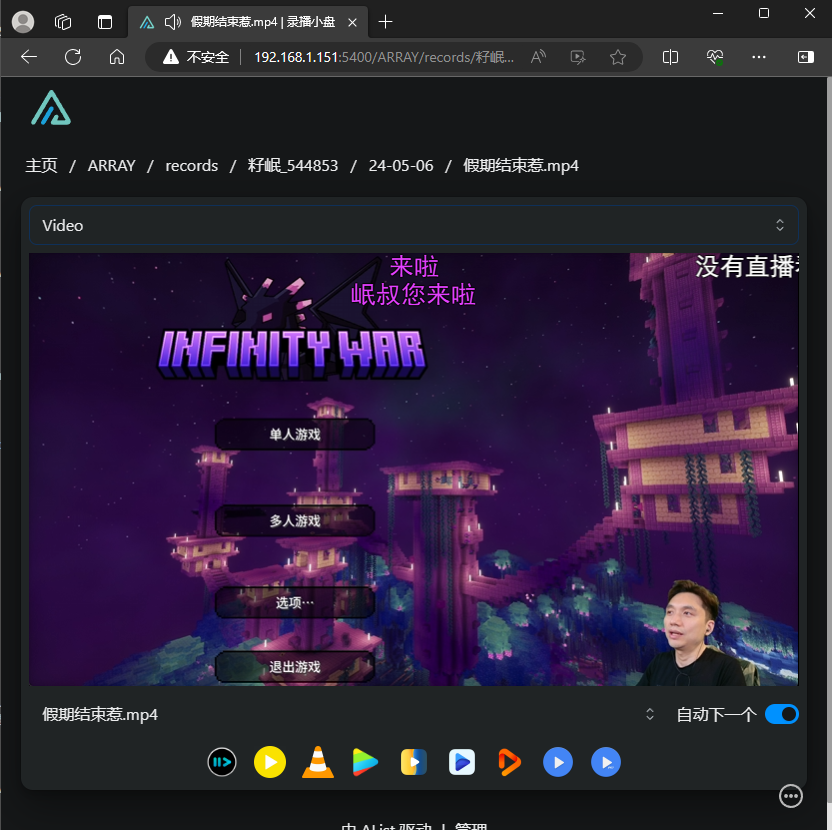
但如果你想要自定义弹幕样式的话,或者遇到一些情况,导致录播视频被切分成了两个文件的话,就会导致第二个文件弹幕与视频不同步,此时就要使用第二张方法,手动转换字幕了。
也就是把xml格式的弹幕转换成ass格式的字幕。同时做一下时间偏移和切分,这样即使录播视频被切成了多个文件,还可以获得相对不错的播放体验。
我这里使用hihkm/DanmakuFactory来做弹幕到字幕的转换,首先需要到G站下载DanmakuFactory的文件,并解压。
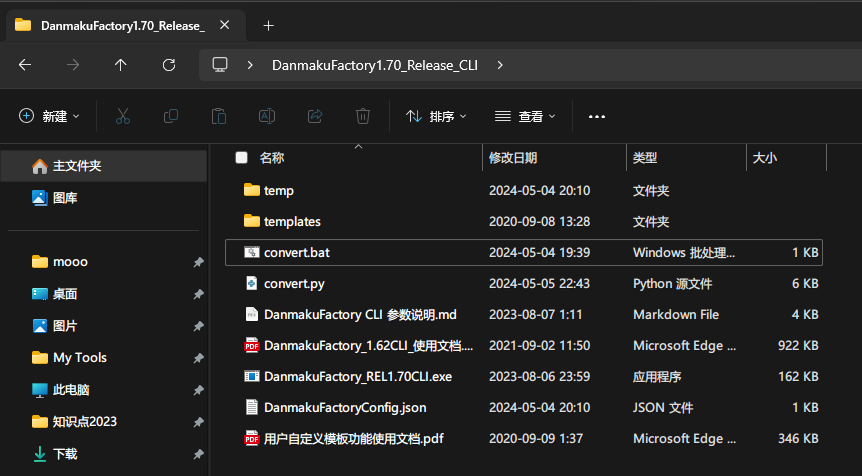
解压好后只有单纯的DanmakuFactory用起来并不方便,我这里专门写了一个python脚本来做自动化的转换工作,文件我会放在文章末尾,是一个bat文件和一个python脚本,没有三方依赖可以直接使用。
大概的过程是调用alist的api下载xml格式的弹幕文件,然后切分并转换成多个ass格式的字幕文件,再上传回alist对应的目录里。
要使用这个脚本,需要将文章末尾的bat文件和python脚本分别保存成convert.bat和convert.py,并放到DanmakuFactory的文件夹里,像这样。
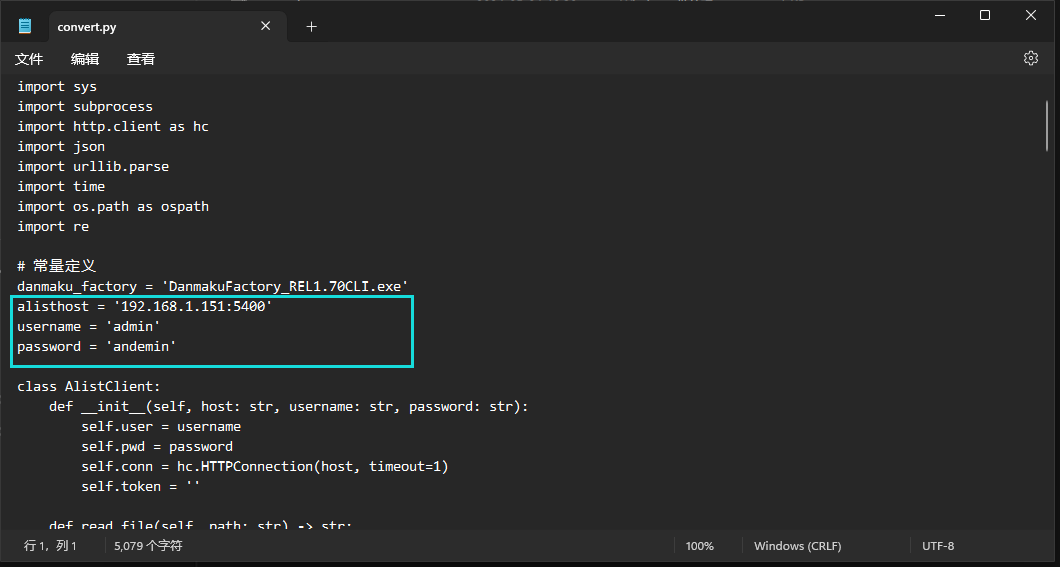
在转换之前还要先编辑python脚本,修改alist的地址和登录的用户密码。
如果是https的alist地址,还需要把第23行的HTTPConnection修改为HTTPSConnection,这样就大功告成了。
然后我们运行bat文件,就可以输入要转行的文件了,这里的参数格式是这样:
<xml弹幕文件路径> [时.分.秒/[时.分.秒/[时.分.秒]]]比如我要转换的弹幕文件是/ARRAY/records/籽岷_544853/24-05-06/假期结束惹.xml,同时录播的时候没有发生网络卡顿,最终录出来的只有单个mp4文件,那么只需要输入/ARRAY/records/籽岷_544853/24-05-06/假期结束惹.xml按回车即可。

上面这种是比较理想的情况,如果录制时网卡了,导致一部分内容没录上,最终录出来的文件可能会变成两个mp4文件,此时就需要指定后面的时间参数了。
时间参数是用来做字幕切分的,比如我们录的时候网卡了,录出两段视频,1.mp4和2.mp4,其中1.mp4录的是从开播开始的0时0分0秒到第1时0分0秒,而中间网卡了一下,导致有十分钟的内容没有录上,那么2.mp4的内容就是1时10分0秒开始,直到主播下播的内容。
这种情况我们就要这样输入参数/path/to/danmu.xml 1.10.0,意思是在1时10分0秒这里切一刀(把1时10分0秒之后的所有弹幕单独复制出来再生成一个ass字幕文件),最终会生成两个ass字幕文件,分别覆盖1.mp4和2.mp4的内容,播放时手动指定一下要加载的字幕文件,这样观看时就不会出现字幕和视频不同步的问题了。(1.10.0也可以简写成1.10,会被识别成1小时10分0秒,同理只有一个一,也就是1会被识别成1小时0分0秒)
如果录出3段视频,那么我们就需要输入两段时间参数了,像这样/path/to/danmu.xml 1.10.0/2.30.0,1.10.0表示从1小时10分切一刀,2.30.0表示从2个半小时这里切一刀,最终会生成3个ass字幕文件,分别覆盖3个视频文件,这样观看就不会有问题啦。
如果使用字幕播放的话,需要在alist的视频播放页面手动关闭弹幕功能,否则弹幕会显示两遍,一遍是弹幕功能,一遍是字幕功能。
最后帖上转换脚本:
convert.bat:(注意bat要用gbk编码保存,否则中文乱码,但不会影响使用。win10/win11的记事本默认使用utf8请注意)
@echo off
:start
SET /p input=输入路径和时间片
python convert.py %input%
echo.
goto startconvert.py:(基于python11编写,无三方依赖库,理论上3.8也可以运行)
from typing import Mapping
import xml.etree.ElementTree as ET
from pathlib import Path
import sys
import subprocess
import http.client as hc
import json
import urllib.parse
import time
import os.path as ospath
import re
# 常量定义
danmaku_factory = 'DanmakuFactory_REL1.70CLI.exe'
alisthost = '192.168.1.151:5400'
username = 'admin'
password = 'andemin'
class AlistClient:
def __init__(self, host: str, username: str, password: str):
self.user = username
self.pwd = password
self.conn = hc.HTTPConnection(host, timeout=5)
self.token = ''
def read_file(self, path: str) -> str:
detail = self.__post('/api/fs/get', { 'path': path, 'refresh': True }, True)
link = re.sub(r'^(https?:\/\/[^\/]+)', '', detail['raw_url'])
return self.__get(link, False)
def write_file(self, path: str, content: str):
data = content.encode()
self.__req('PUT', '/api/fs/put', data, True, {
'File-Path': urllib.parse.quote(path, safe=':/@'),
'Content-Type': 'application/xml',
'Content-Length': len(data)
})
def __auth(self) -> hc.HTTPResponse:
if self.token != '':
return
body = f'{{"username": "{self.user}", "password": "{self.pwd}"}}'
headers = {'Content-Type': 'application/json'}
self.conn.request('POST', "/api/auth/login", body=body, headers=headers)
raw_rsp = self.conn.getresponse()
if raw_rsp.getcode() != 200:
raise raw_rsp
rsp = json.loads(raw_rsp.read().decode())
raw_rsp.close()
if rsp['code'] != 200:
raise rsp
self.token = rsp['data']['token']
def __get(self, path: str, encode_url: bool) -> hc.HTTPResponse:
self.__auth()
if encode_url:
path = urllib.parse.quote(path, safe=':/@')
self.conn.request('GET', path)
raw_rsp = self.conn.getresponse()
if raw_rsp.getcode() != 200:
raise raw_rsp
rsp = raw_rsp.read().decode()
raw_rsp.close()
return rsp
def __req(self, method: str, path: str, body: any, encode_url: bool, headers = {}) -> hc.HTTPResponse:
self.__auth()
if isinstance(body, dict):
body = json.dumps(body)
headers['Content-Type'] = 'application/json;charset=UTF-8'
if encode_url:
path = urllib.parse.quote(path, safe=':/@')
self.conn.request(method, path, body=body, headers={
'Authorization': self.token,
**headers
})
raw_rsp = self.conn.getresponse()
if raw_rsp.getcode() != 200:
raise raw_rsp
rsp = json.loads(raw_rsp.read().decode())
raw_rsp.close()
if rsp['code'] != 200:
raise rsp
return rsp['data']
def __post(self, path: str, body: any, encode_url: bool) -> hc.HTTPResponse:
return self.__req('POST', path, body, encode_url)
def split_filename(path: str):
d = path.rindex('.')
return (path[:d], path[d + 1:])
# 初始化和检查输入
subtitle_path = sys.argv[1]
alist = AlistClient(alisthost, username, password)
# print(sys.argv)
if len(sys.argv) < 2:
print('need a file path followed by time semgents. such /a/b.xml as 1.3.4/5.6')
sys.exit(1)
# 解析时间段
matches = re.findall(r'((\d+\.?)+)+', sys.argv[2]) if len(sys.argv) > 2 else []
if matches is None:
print('wrong foramt')
sys.exit(1)
segments = []
for seg in [seg[0] for seg in matches]:
split = seg.split('.')
while len(split) < 3:
split.insert(0, '0')
segments.append(split)
# 添加自己
segments.insert(0, (0, 0, 0))
# 切分字幕
offset = 0
index = 0
for (h, m, s) in segments:
# 按时间进行过滤
duration = float(h) * 60 * 60 + float(m) * 60 + float(s)
offset += duration
danmu_content = alist.read_file(subtitle_path)
root = ET.fromstring(danmu_content)
delete = []
for node in root:
if node.tag != 'd':
continue
p = node.attrib['p']
delimiter = p.index(',')
time = float(p[:delimiter])
rest = p[delimiter + 1:]
time -= offset
if time < 0:
delete.append(node)
else:
node.attrib['p'] = f'{time:.3f},{rest}'
for n in delete:
root.remove(n)
# 将弹幕转换为字幕格式,并上传
temp_in_file = Path('temp/in.xml').absolute()
temp_out_file = Path('temp/out.ass').absolute()
temp_in_file.parent.mkdir(exist_ok=True)
temp_out_file.parent.mkdir(exist_ok=True)
# 写入临时文件
with open(temp_in_file, 'wb') as f:
f.write(ET.tostring(root, encoding='utf-8'))
# 转换格式
cli = f'{danmaku_factory} -i "{temp_in_file}" -o "{temp_out_file}" --ignore-warnings'
# print(cli)
subprocess.run(cli, check=True)
# 上传
full, ext = split_filename(subtitle_path)
remote_filename = f'{full}_弹幕{index + 1}.ass'
with open(temp_out_file, 'rb') as f:
alist.write_file(remote_filename, f.read().decode())
print(f'时间片段: {h}小时 {m}分钟 {s}秒: {remote_filename}')
index += 1
# print('ok')